| Product(s): |
WaterGEMS, WaterCAD, SewerGEMS |
| Version(s): |
10.00.00.50 and later (Water), 10.01.00.70 and later (SewerGEMS) |
| Area: |
Modeling |
| Original Author: |
Wayne Hartell, Principle Software Engineer, Bentley Systems |
Background
This document describes how to edit the custom queries for SCADAConnect Simulator. Both historical queries and real-time queries are covered.
Why would you want to define custom SCADAConnect queries?
SCADAConnect defines default queries that are designed to work with the maximum number of 3rd party databases, including a number of specific connection types including Excel, Access, SQL Server, ODBC, OLE DB and Oracle (for the database connection types). There are, however, many types of 3rd party databases and different kinds of drivers available, which ultimately means that not all SQL statements will work the same on all databases. Some might work fine, others sub-optimally, and others potentially not at all. Furthermore, some databases have specially optimized SQL keywords and constructs that allow users to leverage database specific performance optimizations. What works really well for one system, might not do so for the next. For these reasons, it is possible for users to edit the SQL statements used by SCADAConnect, in order to ensure that SCADAConnect works in the best possible way with the specific database system that is being connected to.
Note: It is highly recommended that when implementing custom queries that you verify that the queries work as expected on the native database system before using them with SCADAConnect. This will help eliminate the query string as the source of any error in the event of a problem reading the SCADA data using SCADAConnect. Some of the custom queries utilize special variables (prefixed with the ampersand '@' symbol) and so it is necessary to know how those variables are replaced by SCADAConnect so that verbatim test queries can be written. These variables (and how they are expanded by SCADAConnect) is described below.
Some definitions
Before getting into the details it will make things easier to digest if we first explain a few terms.
Source Format
This property of a database connection describes the format of the data that SCADAConnect must read. There are two supported values: One value per row and Multiple values per row.
One value per row is when the database tables are configured such that there is a different column for signal/tag name, time stamp, data value and optionally data quality. Every row contains a different data point for a specific signal/tag, hence the nomenclature one value per row.
Multiple values per row is when the database tables are configured such that there is a column for time stamp, and a unique column for every signal/tag. In this situation, for every time stamp, there will be data populated for multiple signals/tags. Using this format prevents a data quality value from being assigned or read. Typically, data will be in the one value per row format.
Historical vs Real-time
This property of a database connection determines whether SCADAConnect tries to read real-time data or historical data from the data source. The goal for a real-time read is to read the latest available value for a signal/tag, whereas a historical read will try to find the value closest to a requested time stamp, subject to a user defined time tolerance (if no values exist inside the tolerance, no data will be read).
Custom Query Variables
As will become apparent further down in this document, SCADAConnect supports user customizable queries through the use of certain reserved variables. These variables are prefixed with the ampersand '@' symbol and are replaced by SCADAConnect when reading data in order to construct the full query. The currently supported variables are:
@requestedsignals: Used to represent the list of signals/tags. This variable is replaced with a comma separated list of signal/tag names. (e.g., Signal1, Signal2, Signal3). This is the required formatting when coupled with the SQL IN keyword.
@requestedsignals_or: Used to represent the list of signals/tags. This variable is replaced with list of signal/tag name concatenated with the OR keyword. (e.g., Signal1 or Signal1 or Signal3). This is the required formatting when coupled with the SQL OR keyword.
Most database historical queries will default to using the SQL IN keyword as follows:
from 'table_name' where 'signal_name' in (@requestedsignals)
If, however, your database does not support the IN keyword, you can edit the query to remove the 'signal_name' in portion of the query. This will change it to support the use of SQL OR, however, you also need to tell SCADAConnect that this is your intention by using the @requestedsignals_or variable. i.e., change the default query to look like this:
from 'table_name' where (@requestedsignals_or)
This ensures that SCADAConnect replaces the @requestedsignals variable with correctly formatted signals names (in this case Signal1 or Signal1 or Signal3) as mentioned above.
@startdatetime: Used to represent the start of a time range for historical connections.
@enddatetime: Used to represent the end of a time range for historical connections.
Note: The @requestedsignals variable should be enclosed in round brackets in earlier versions of SCADAConnect. In the latest available software versions (WaterGEMS 10.01.01.04 and SewerGEMS 10.01.01.04), the variable will be automatically included inside curved brackets if required, when SCADAConnect does the variable replacement.
Note: The @requestedsignals_or variable is only available in the latest software versions (WaterGEMS 10.01.01.04 and SewerGEMS 10.01.01.04), when the latest patch sets are applied.
Note: When manually testing queries in the native database, it will be necessary to manually substitute the literal value of the variable.
Note: The @startdatetime and @enddatetime variables can be optionally (and only in the latest software versions with latest patch sets applied) used to override the date time format by specifying the desired date time format inside a set of brackets as follows.
@startdatetime("custom_date_time_formatter_string")
This can be used to override the default formatter string which is, for most database types "dd-MMM-yyyy HH:mm:ss".
For more information on what constitutes a valid date time format string, please check this Microsoft link
You may specify the custom date time format in either variable (start or end) or in both. In the case both variables are used and the custom string differs, the one associated with the @startdatetime variable will be used.
Note: It is strongly recommended that if using SCADAConnect is important to you that you ensure you are using the latest software version with all available updates.
The default queries
The database connections in SCADAConnect support editing the SQL Statements by way of the SQL Statements… button at the bottom of the Database Source dialog. If you click this button you will be presented with a set of default queries that are based on the settings you have selected for Source Format and also whether the data source is real-time or historical.
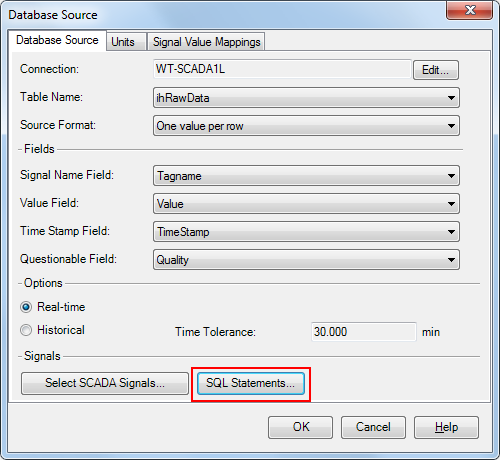
If you click on the Customize SQL Statements check box, the default queries become editable. The following image shows the default custom queries for a real-time data source with a source format of one value per row.
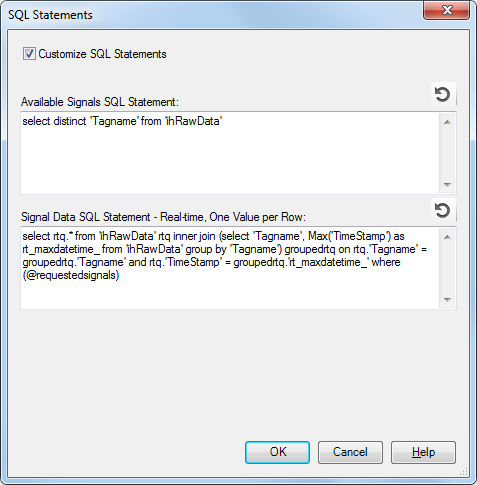
As you can see, the default query for creating the list of signals or tags is straightforward and may be suitable often, however, the second SQL statement is more complicated. Each of the different kinds of SQL statements are covered below in more detail.
Available Signals SQL Statement
(Applies to Historical and Real-time, One value per row only).
select distinct signal_name from table_name
This statement is expected to return a table/view with the first column representing the signal name or label. The returned data set should seek to only return unique signal names, however, it is not essential, since SCADAConnect will eliminate duplicate entries.
Note: For some data sources such as GE Historian it may be more efficient to acquire signal/tag names from a different table (e.g., ihTags).
Signal Data SQL Statement - Real-time, One Value per Row
(Applies to Real-time, One value per row).
select rtq.* from ['table_name'] rtq inner join (select [signal_name], Max([DateTime]) as rt_maxdatetime_ from ['table_name'] group by [signal_name]) groupedrtq on rtq.[signal_name] = groupedrtq.[signal_name] and rtq.[DateTime] = groupedrtq.[rt_maxdatetime_] where rtq.[signal_name] in (@rtq.requestedsignals)
The default statement appears to be somewhat complex. Most of the complexity is the direct result of needing to keep the statement generic and applicable to the widest number of systems. This query employs an SQL alias (rtq; i.e., real time query) coupled with an SQL inner join to find the value for each signal/tagname with the most recent time stamp. A table/view with a column for signal/tag name, value, timestamp and quality should be answered by the query.
The signal/tag names used in the query are derived from the @requestedsignals variable.
Note: Further down in this document an example of an optimized (and much simpler looking) query (for GE Historian) is provided, that achieves the same result (the default query does not work with GE Historian). Look for the query with "samplingmode=CURRENTVALUE".
Signal Data SQL Statement - Real-time, Multiple Values per Row
(Applies to Real-time, Multiple values per row).
select rtq.* from ['table_name'] rtq inner join (select Max([DateTime]) as rt_maxdatetime_ from ['table_name']) groupedrtq on rtq.[DateTime] = groupedrtq.[rt_maxdatetime_]
This query is similar to the one for multiple values per row, including the rationale behind it. The implicit assumption with this query is that there is a value present in every signal/tagname column for the latest time stamp.
Signal Data SQL Statement - Historical, One Value per Row
(Applies to Historical, One value per row).
select [signal_name],[data_value],[DateTime],[Questionable] from ['table_name'] where [signal_name] in (@requestedsignals) and (([DateTime]>=@startdatetime) and ([DateTime]<=@enddatetime))
This default query is a lot simpler than its real-time counterpart. It simply queries a table that contains the signal/tagname column, value column, timestamp column and optionally the quality column, for the appropriate signals as denoted by the @requestedsignals variable. It further utilizes the @startdatetime and @enddatetime variables to limit the range of the result set that is answered to the range of interest.
Signal Data SQL Statement - Historical, Multiple Values per Row
(Applies to Historical, Multiple values per row).
select @requestedsignals,[DateTime] from ['table_name'] where (([DateTime]>=@startdatetime) and ([DateTime]<=@enddatetime))
This default query simply selects the signal/tag columns and the time stamp column from the source table, utilizing the @requestedsignals variable. It further utilizes the @startdatetime and @enddatetime variables to limit the range of the result set that is answered to the range of interest.
Date/Time Range SQL Statement
(Applies to Historical).
select Min([DateTime]),Max([DateTime]) from ['table_name']
This query is used to determine the date range of data in a table. This is leveraged by SCADAConnect to avoid querying for data that cannot exist since doing so can often be inefficient.
When to edit the default queries
As discussed at the start of this document there could be multiple reasons for wanting to edit SCADAConnect's custom queries. Most of these reasons will boil down to some kind of database incompatibility with the a default query (or queries), or it may be that the database being used offers a more efficient (possibly proprietary) method for acquiring the necessary data.
You may need to edit the default queries if:
- The default queries do not work with your database,
- The default queries work, but your database vendor provides more efficient SQL options for querying your data,
- A combination of both the above,
- Your data needs to be pre-processed before it can be used,
- Your data exists in multiple different table,
- Your real-time database does not support timestamps.
- Possibly other reasons not listed.
The GE Proficy Historian is one good example of case #3. As mentioned earlier, the default Signal Data SQL Statement does not work with this database; however, the database provides a more efficient way of retrieving real-time data. We'll use this specific example to illustrate how to edit custom queries.
How to edit the real-time queries
To edit the SQL queries you simply have to type into the available boxes. It is recommended that someone with database.SQL experience does this, though it is possible to reset to the default query at any time by clicking the reset button for each query (top right of the query text box), or turn of the use of customized queries by unchecking the Customize SQL Statements check box.
Using some customized SQL queries for GE Proficy Historian as an example, the query for Signal Data SQL Statement has been modified as shown.
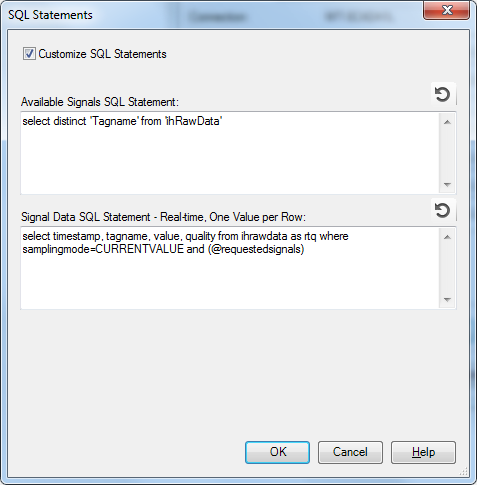
The portion of the SQL statement samplingmode=CURRENTVALUE tells the GE Historian database to fetch the latest value for the particular field/tagname. This replaces all the extra SQL that was devoted in the default query to execute the inner join and is the preferred way for the GE Historian database.
Note: The image above shows as part of the signal data query the words "as rtq". This is a requirement in earlier versions of SCADAConnect due to a quirk present in those versions. The quirk is related to the default SQL statement, that we have already examined above, which uses the rtq alias in the SQL statement that defines the inner join. Thus, SCADAConnect is expecting to see that alias in use for the table where the signal name(s) (tag name(s)) are present. The result of the quirk is that in the initial CONNECT releases of the Bentley OpenFlows products, the "as rtq" part of the customized statement is necessary to include for the custom query to work correctly. In the latest product versions, however, the custom real-time query does not require the inclusion of the rtq alias (via "as rtq"), though any custom queries that do include the "as rtq" alias will still work.
See Also
SCADAConnect Simulator for WaterGEMS (V8i SELECTseries 6 and CONNECT edition)